Also question is, what is WordNetLemmatizer Python?
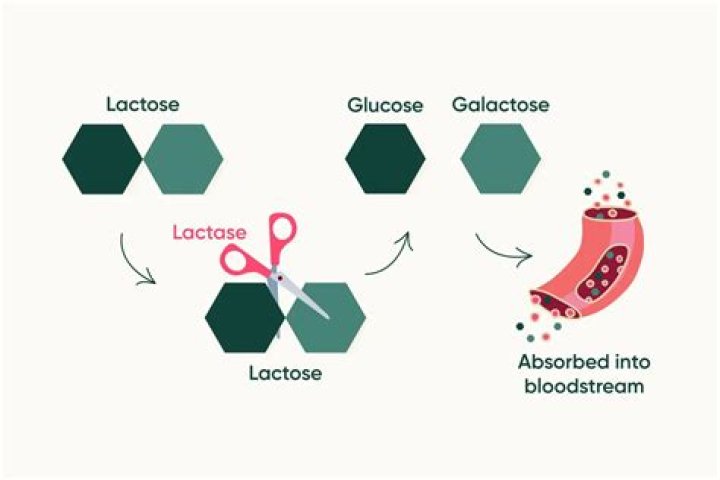
Python | Lemmatization with NLTK. Lemmatization is the process of grouping together the different inflected forms of a word so they can be analysed as a single item. Lemmatization is similar to stemming but it brings context to the words. So it links words with similar meaning to one word.
Similarly, what is Lemmatization in NLP? Lemmatization (or lemmatization) in linguistics is the process of grouping together the inflected forms of a word so they can be analyzed as a single item, identified by the word's lemma, or dictionary form.
Moreover, what is the difference between stemming and Lemmatization?
Stemming and Lemmatization both generate the root form of the inflected words. The difference is that stem might not be an actual word whereas, lemma is an actual language word. Whereas, in lemmatization, you used WordNet corpus and a corpus for stop words as well to produce lemma which makes it slower than stemming.
Which process of NLP normalizes words into base or root form?
The goal of both stemming and lemmatization is to "normalize" words to their common base form, which is useful for many text-processing applications. Stemming = heuristically removing the affixes of a word, to get its stem (root).
How do you use WordNetLemmatizer?
In order to lemmatize, you need to create an instance of the WordNetLemmatizer() and call the lemmatize() function on a single word. Let's lemmatize a simple sentence. We first tokenize the sentence into words using nltk. word_tokenize and then we will call lemmatizer.Why is stemming important?
Stemming is the process of reducing a word to its word stem that affixes to suffixes and prefixes or to the roots of words known as a lemma. Stemming is important in natural language understanding (NLU) and natural language processing (NLP). When a new word is found, it can present new research opportunities.What is WordNet used for?
WordNet is a lexical database (a collection of words) that has been used by major search engines and IR research projects for many years. WordNet can be used to get information about the following for a given word or phrase: Synonyms - Words that have the same meaning (soil = dirt)What is NLTK in Python?
The Natural Language Toolkit (NLTK) is a platform used for building Python programs that work with human language data for applying in statistical natural language processing (NLP). It contains text processing libraries for tokenization, parsing, classification, stemming, tagging and semantic reasoning.Is stemming or Lemmatization better?
The real difference between stemming and lemmatization is threefold: Stemming reduces word-forms to (pseudo)stems, whereas lemmatization reduces the word-forms to linguistically valid lemmas.How do you tokenize a string in Python?
Few examples to show you how to split a String into a List in Python.- Split by whitespace. By default, split() takes whitespace as the delimiter. alphabet = "a b c d e f g" data = alphabet.
- Split + maxsplit. Split by first 2 whitespace only. alphabet = "a b c d e f g" data = alphabet.
- Split by # Yet another example.
What is POS NLP?
A Part-Of-Speech Tagger (POS Tagger) is a piece of software that reads text in some language and assigns parts of speech to each word (and other token), such as noun, verb, adjective, etc., although generally computational applications use more fine-grained POS tags like 'noun-plural'.How do you remove stop words in Python?
Natural Language Processing: remove stop words- from nltk.tokenize import sent_tokenize, word_tokenize.
- from nltk.corpus import stopwords.
- data = "All work and no play makes jack dull boy. All work and no play makes jack a dull boy."
- stopWords = set(stopwords.words('english'))
- for w in words:
- if w not in stopWords:
What is the purpose of Lemmatization?
Lemmatization usually refers to doing things properly with the use of a vocabulary and morphological analysis of words, normally aiming to remove inflectional endings only and to return the base or dictionary form of a word, which is known as the lemma .How does a porter Stemmer work?
The Porter stemming algorithm (or 'Porter stemmer') is a process for removing the commoner morphological and inflexional endings from words in English. Its main use is as part of a term normalisation process that is usually done when setting up Information Retrieval systems.What is POS machine learning?
Part-of-Speech tagging is a well-known task in Natural Language Processing. It refers to the process of classifying words into their parts of speech (also known as words classes or lexical categories). This is a supervised learning approach.What does stemmed from mean?
Definition of stem from. : to be caused by (something or someone) : to come from (something or someone) Most of her health problems stem from an accident she had when she was younger.What is the lemma of a word?
Lemma (linguistics) A lemma is the word you find in the dictionary. A lexeme is a unit of meaning, and can be more than one word. A lexeme is the set of all forms that have the same meaning, while lemma refers to the particular form that is chosen by convention to represent the lexeme.What is a snowball Stemmer?
Snowball. Snowball is a small string processing language designed for creating stemming algorithms for use in Information Retrieval. The Snowball compiler translates a Snowball script into another language - currently ISO C, C#, Go, Java, Javascript, Object Pascal, Python and Rust are supported.What is tokenization in NLP?
NLP | How tokenizing text, sentence, words works. Tokenization is the process of tokenizing or splitting a string, text into a list of tokens. One can think of token as parts like a word is a token in a sentence, and a sentence is a token in a paragraph.Why tokenization is important in NLP?
Tokenization does this task by locating word boundaries. Ending point of a word and beginning of the next word is called word boundaries. These tokens are very useful for finding such patterns as well as is considered as a base step for stemming and lemmatization.What are stop words in NLP?
Removing stop words with NLTK in Python- What are Stop words?
- Stop Words: A stop word is a commonly used word (such as “the”, “a”, “an”, “in”) that a search engine has been programmed to ignore, both when indexing entries for searching and when retrieving them as the result of a search query.